spring中使用Quartz
网上看到很多Quartz的帖子,说得都很不错,关于他的由来和原理我这里就不累赘了。我主要想解决的事情是一开始我遇到的无法自动启动的问题。
用例子说话。
一、写一个自定义的类,继承至Object就可以了。并且可以配合set方法,用于在spring中注入。
二、配置文件
在spring的配置文件中,增加下面的配置
<property name="message">
<value>nihao</value>
</property>
</bean>
<bean id="poolingDetail"
class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject">
<ref bean="poolingSendMail"/>
</property>
<property name="targetMethod">
<value>setMessage</value>
</property>
</bean>
<bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail">
<ref bean="poolingDetail"/>
</property>
<property name="cronExpression">
<value>* 5 1 ? * MON-FIR</value>
</property>
</bean>
<bean id ="schedulerFactory" lazy-init="false" autowire="no"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref local="cronTrigger" />
</list>
</property>
<property name="autoStartup" value="true"/>
<property name="schedulerName" value="cronScheduler" />
</bean>
经过这样的简单配置就可以让程序在周一到周五的凌晨1点5分的某个时刻执行程序了。(当然这里只是简单的system.out动作而已)
刚开始的时候,一直困扰我的是我在启动tomcat后,无法自动启动定时任务。但是我如果在java中直接获取spring配置文件,并获取我“schedulerFactory” 是可以运行的。
后来问题终于找到。是刚开始的时候,我没有落了几个需要设置的地方
1. bean “schedulerFactory“ 的lazy-init="false”。
2. bean “schedulerFactory“ 的两个属性
<property name="autoStartup" value="true"/>
<property name="schedulerName" value="cronScheduler" />
完成上面的设置后,程序就可以自动启动了。yeah。give me five。。
struts 1.x 学习 ---持续更新
最后更新:2009-5-12
1.可以通过在web.xml这配置,统一管理项目中的error显示页面。强……
<error-code>404</error-code>
<location>/commom/404.jsp</location>
</error-page>
<error-page>
<error-code>500</error-code>
<location>/commom/500.jsp</location>
</error-page>
如果需要对特定类型的error做显示,还可以设定 <exception-type>来达到效果
<exception-type>javax.servlet.ServletException</exception-type>
<location>/commom/system_error.jsp</location>
</error-page>
<error-page>
<exception-type>java.io.IOException</exception-type>
<location>/commom/system_ioerror.jsp</location>
</error-page>
oracle 使用心得。持续更新
- 在jdbc中使用sequence,需要在之前先使用query语句得到新的sequence值。例如:
SELECT 'schema'.'sequence's name'.nextval from dual;--seqNum 就是上面得到的sequence新值
insert into table (id,name) values(seqNum, 'poker');
commit;
struts标签的使用
strusts标签挺好用的,但是在使用过程中可能会遇到一些很莫名的问题。这里罗列一些出来,会持续更新... last update:2009/5/5
- 如果想在Struts标签中的 value属性中添加变量,不可以使用struts标签嵌套。因struts不支持标签嵌套,可采用EL来解决该问题。例如:
......
</logic:equal>
Philippe Kruchten's 4+1 view model
在学习OReilly.Learning.UML.2.0.Apr.2006.chm的时候,看到有这部分的知识,不明白,但知道很重要,就上网查了一下。做了汇总。
以下首先是 4+1 图。。。

Figure 1-1. Philippe Kruchten’s 4+1 view model
由于Learning.UML中,在这个图下面就是几段文字性的叙述,感觉不够形象,还是心智图比较好用。在网上找的,贴上

Figure 1-2. Diagrams overview (created by FreeMind, http://freemind.sourceforge.net)
上面的两幅图片均来至:http://www.hooto.com/home/flyhigh/?cp=blog&op=blog&iid=1330
感谢Rui's log。。让我还找到了两个很棒的软件,
1、Visual Paradigm for UML Community Edition http://www.visual-paradigm.com(制作UML)
2、FreeMind, http://freemind.sourceforge.net(专门绘制心智图)
项目开发模型(Software Development Process)
第一种:瀑布模型(Waterfall Model)
它发现项目开发中最经常用的开发模型
所有过程模型的鼻祖。---- Royce,1970
瀑布模型把软件开发过程划分成若干阶段,每个阶段的任务相对独立,便于不同人员分工协作,从而降低了整个软件开发工程的困难程度。在软件生存期的每个阶段都采用科学的管理技术和良好的方法与技术,而且每个阶段结束之前,都从技术和管理两个角度进行严格的审查,经确认之后才开始下一阶段的工作。---- 项目是按照一定的顺序执行。
瀑布模型是文档驱动的,各个阶段不连续也不交叉。
特点:
1.阶段间具有顺序性和依赖性。
2.推迟程序的物理实现。
3.质量保证:每个阶段必须完成规定的文档;每个阶段结束前完成文档审查,及早改正错误。
4.易于组织,易于管理:因为你可以预先完成所有计划。
5.是一种严格线性的、按阶段顺序的、逐步细化的过程模型(开发模式)
适用场合:
1.当有一个稳定的产品定义和很容易被理解的技术解决方案时,纯瀑布模型特别合适。
2.当你对一个定义得很好的版本进行维护或将一个产品移植到一个新的平台上,瀑布模型也特别合适。
3.对于那些容易理解但很复杂的项目,采用纯瀑布模型比较合适,因为可以用顺序方法处理问题。
4.在质量需求高于成本需求和进度需求的时候,它尤为出色。
5.当开发队伍的技术力量比较弱或者缺乏经验时,瀑布模型更为适合。
缺陷:
1.在项目开始的时候,用户常常难以清楚地给出所有需求;用户与开发人员对需求理解存在差异。
2.实际的项目很少按照顺序模型进行。
3.缺乏灵活性:因为瀑布模型确定了需求分析的绝对重要性,但是在实践中要想获得完善的需求说明是非常困难的,导致“阻塞状态”。反馈信息慢,开发周期长。
4.虽然存在不少缺陷,瀑布模型经常被嘲笑为“旧式的”,但是在需求被很好地理解的情况下,仍然是一种合理的方法。
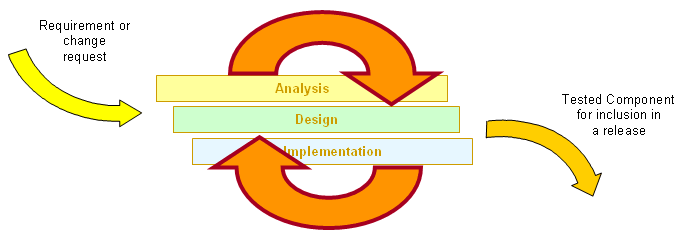
第二种:迭代模型(terative Model)

从开发人员角度进行的迭代模型如下图:
对众多的开发模型和过程方法,及权威机构的看法,企业应选择什么样的开发模型,应慎重对从以下几方面进行考虑:
1、RUP虽然内容极其丰富,定义了选起、精化、构建、产品化4个阶段和业务建模、需求、分析设计、实现、测试、部署等9个工种,提供了一大堆的文档模板,但极易让人误解是重型的过程,实施推广有一定难度。
2、再次,在质量管理方面:以实现系统架构、核心功能目标的迭代产品生的工作成果作为质量控制重点。每次迭代进行系统集成、系统测试,达到对软件质量的持续验证。每次系统测试,需要回归测试前一次迭代遗留发现的问题。每次迭代发布的小版本组织客户(包括内部客户、外部客户)进行评价,通过演示操作等方式,评价该次迭代是否达到预定的目标,并以此为依据来制定下一次迭代的目标。
3、最后,在其他方面:每次迭代成果须进行配置管理,版本控制很重要。在整个迭代过程中风险无处不在,建议每周作一次风险跟踪。同时通过重点关注进度、工作量、满意度、缺陷等数据收集,关注每次迭代情况。
总之,选择一个合适的生命周期模型,并应用正确的方法,对于任何软件项目的成功是至关重要。企业在选择开发模型应从项目时间要求、需求明确程度、风险状况等选择合适的生命周期模型。
1、在项目开发早期需求可能有所变化。
2、分析设计人员对应用领域很熟悉。
3、高风险项目。
4、用户可不同程度地参与整个项目的开发过程。
5、使用面向对象的语言或统一建模语言(Unified Modeling Language,UML)。
6、使用CASE(Computer Aided Software Engineering,计算机辅助软件工程)工具,如Rose(Rose是非常受欢迎的物件软体开发工具。)。
7、具有高素质的项目管理者和软件研发团队。
与传统的瀑布模型相比较,迭代过程具有以下优点:
1)降低了在一个增量上的开支风险。如果开发人员重复某个迭代,那么损失只是这一个开发有误的迭代的花费。
2)降低了产品无法按照既定进度进入市场的风险。通过在开发早期就确定风险,可以尽早来解决而不至于在开发后期匆匆忙忙。
3)加快了整个开发工作的进度。因为开发人员清楚问题的焦点所在,他们的工作会更有效率。
4)由于用户的需求并不能在一开始就作出完全的界定,它们通常是在后续阶段中不断细化的。因此,迭代过程这种模式使适应需求的变化会更容易些。
第三种:敏捷开发模式(ASD: Agile Software Development)
这个是一个概念性的东西,网上也普遍引用敏捷宣言(Manifesto for Agile Software Development)。对于上上来的两个比较有见解的文章,这里剪辑一下。
文章出处:
1.http://www.ruby-lang.org.cn/forums/thread-604-1-1.html
作者是bryanzk。很有思想。
2.http://www.cybersoftek.com/index.php?option=com_content&task=view&id=8&Itemid=1
里面的内容是转载自吴穹博士的文章。
敏捷软件开发是一个概念意义上的框架,用来取代软件工程项目的概念;它强调在项目的整个生命周期中,拥抱并促进由于软件进化式的发展所带来的变化。
Agile software development is a conceptual framework for undertaking software engineering projects that embraces and promotes
evolutionary change throughout the entire life-cycle of the project.
这段定义来自wikipedia,我认为是我接触ASD以来,对ASD最精辟的论述。
请注意其中的三个关键词:
在项目的整个生命周期中:这就涉及到了【敏捷项目管理】、【敏捷需求获取】、狭义的【敏捷软件开发】三个主要的领域和过程。要注意的是,上述三个过程并不是互相分开的,而是你中有我,我中有你。
拥抱并促进变化:世界上唯一不变的是变化。不论在任何领域,漠视、甚至否认、抗拒变化,都不是一个理性,严肃的人所应有的态度。学会如何识别变化的大势,并在可能的时候,促使变化向好的方向发展。这才是面对变化的正确应对之法。
软件进化式的发展:虽然上面提到促进变化的发展,但是软件的演化过程,我相信是有其自身内在逻辑的,存在一些根本规律和指导方针;并不是完全以人的主观意识为主导。
关于敏捷软件开发,在Wikipedia中找到了下面的定义:
(Agile Software Development is a conceptual framework for software development that promotes development iterations, open collaboration, and adaptability throughout the life-cycle of the project.)
在这个定义中,指出了敏捷的三个要素:迭代开发、坦诚合作和自适应性,下面我们分别对这三个要素进行以下分析。
下面是Wiki里有关敏捷和其他迭代开发方法的异同:
绝大多数敏捷方法都沿用了迭代和增量式的开发方法,强调在短时间段内构建可以发布的软件。敏捷开发与其他开发模型的不同之处在于:时间段是按周而不是按月进行度量的,工作也以高度协作的方式展开。同样区分于其他模型的是,绝大多数敏捷方法将时间段限制为严格定死的时间盒。
(Most agile methods share other iterative and incremental development methods' emphasis on building releasable software in short time periods. Agile development differs from other development models: in this model time periods are measured in weeks rather than months and work is performed in a highly collaborative manner. Most agile methods also differ by treating their time period as a strict timebox.)
坦诚合作其实才是敏捷的精髓,如Ivar所说,敏捷其实是有关Social Engineering的。敏捷的主要贡献在于他更多地思考了如何去激发开发人员的工作热情,这是在软件工程几十年的发展过程中相对被忽略的领域。如何将敏捷融入到整个软件工程的体系当中,这将是下一篇文章讨论的内容。
自适应性其实是一种后退,但是一种明智的、合理的后退。长期以来,人们经常试图将成功应用于建筑、机械等其他领域的项目管理方法强加到软件身上。这些方法往往非常强调可预测性,但由于软件本身的特性,往往给开发过程增加了不必要的成本。正如Walker Royce所说,开发软件其实更象拍电影,所以管理的挑战更大。敏捷提出的自适应性其实是减低了对项目可预测性的不合理要求,解放团队让他们关注与交付客户价值。
自适应方法关注快速适应不断变化的现实情况。随着项目需求的变化,自适应的团队也会随之而变。自适应团队很难准确预测未来的状况。(来自Wikipeida)
Adaptive methods focus on adapting quickly to changing realities. When the needs of a project change, an adaptive team changes as well. An adaptive team will have difficulty describing exactly what will happen in the future. (from Wikipedia)
重温一下敏捷宣言---Agile Manifesto:
- 人和交互重于过程和工具。
- 可以工作的软件重于求全责备的文档。
- 客户合作重于合同谈判。
- 随时应对变化重于循规蹈矩。
- Individuals and interactions over processes and tools.
- Working software over comprehensive documentation.
- Customer collaboration over contract negotiation.
- Responding to change over following a plan.
以下十一条是Agile Manifesto背后的基本原则,其实你可以看到前四条是有关迭代的, 后六条是有关团队合作的,最后一条是有关自适应性的。
- 通过快速,持续地交付可用的软件让客户满意。
- (按周而不是按月)频繁交付可用的软件。
- 可用的软件是首要的进度度量标准。
- 欢迎需求变更,即使来的很晚。
- 业务人员和开发人员要尽量做到每天在一起紧密工作。
- 面对面的谈话是最好的沟通方式,(在同一地点工作)。
- 参与项目的人员都应该抱有积极的态度。而且他们也得到信任。
- 持续关注技术的卓越程度和良好的设计。
- 简单至上。
- 构建自组织的团队。
- 让团队有规律地适应不断变化的环境。(以上11条来自Wikipedia)
- Customer satisfaction by rapid, continuous delivery of useful software.
- Working software is delivered frequently (weeks rather than months).
- Working software is the principal measure of progress.
- Even late changes in requirements are welcomed.
- Close, daily cooperation between business people and developers.
- Face-to-face conversation is the best form of communication (Co-location).
- Projects are built around motivated individuals, who should be trusted.
- Continuous attention to technical excellence and good design.
- Simplicity.
- Self-organizing teams.
- Regular adaptation to changing circumstances.(from Wikipedia).
面对时下火热的敏捷运动,首先是不要神化,不要迷信,不要迷失自我。存在即合理,你先有的开发流程和工作方式一定有它的合理性,应渐进地采纳敏捷中一些合适的实践,仔细审视各种工件的合理性和必要性,要防止借敏捷的旗号来偷工减料(尤其是放弃必要的设计和架构工作)。同时,也应该充分利用这次文化运动所产生的变革力量和热情,推动一些最佳实践(如迭代开发),打破一些对软件开发活动不合理的束缚。总之,要弄潮,而不要被潮水裹挟,Be Smart。
正则表达式符号列表
正则表达式符号列表
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
将Struts 应用程序移植到 JSF
清单 5. 在 web.xml 中声明 FacesServlet
<servlet>
<servlet-name>faces</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<!-- JavaServer Faces Servlet Mapping -->
<servlet-mapping>
<servlet-name>faces</servlet-name>
<url-pattern>/faces/*</url-pattern>
</servlet-mapping>
<%@ taglib uri="http://jakarta.apache.org/struts/tags-faces"prefix="s" %>
<!-- Layout component parameters: header, menu, body, footer -->
<s:html>
<head>
<title> <tiles:getAsString name="title"/></title>
<s:base/>
</head>
<body>
<TABLE border="0" width="100%" cellspacing="5">
<tr>
<td><tiles:insert attribute="header"/></td>
</tr>
<tr>
<td><tiles:insert attribute="body"/></td>
</tr>
<tr><td><hr></td></tr>
<tr>
<td><tiles:insert attribute="footer" /></td>
</tr>
</TABLE>
</body>
</s:html>
<definition name="foobar.master-layout"
path="/faces/layout/MasterLayout.jsp">
<put name="title" value="Welcome to Foo Bar Travels" />
<put name="header" value="/faces/common/header.jsp" />
<put name="footer" value="/faces/common/footer.jsp" />
<put name="body" value="" />
</definition>
<!-- Definition for Flight Search Page -->
<definition name="/foobar.flight-search"
extends="foobar.master-layout">
<put name="body" value="/faces/FlightSearch.jsp" />
</definition>
Tree tree = context.getTree();
String requestURI = context.getTree().getTreeId();
rd = request.getRequestDispatcher(requestURI);
/** If the response is committed, include the resource **/
if( !response.isCommitted() ) {
rd.forward(request, context.getServletResponse());
}
else {
rd.include(request, context.getServletResponse());
}
LifecycleFactory factory = (LifecycleFactory)
FactoryFinder.getFactory("javax.faces.lifecycle.LifecycleFactory");
//Get the context param from web.xml
String lifecycleID =
getServletContext().getInitParameter("javax.faces.lifecycle.LIFECYCLE_ID");
//Get the Lifecycle Implementation
Lifecycle lifecycle = factory.getLifecycle(lifeCycleID);
LifecycleFactory factory = (LifecycleFactory)
FactoryFinder.getFactory("javax.faces.lifecycle.LifecycleFactory");
//Create a new instance of Lifecycle implementation -
//com.sun.faces.lifecycle.LifecycleImpl
//According to the documentation, factory.getLifecycle("STFLifecycle")
//should work, but JSF-RI has a defect.
//Hence this workaround of creating a RI class explicitly.
LifecycleImpl stfLifecycleImpl = new LifecycleImpl();
//Create a new instance of our STFViewHandler and set it on the Lifecycle
stfLifecycleImpl.setViewHandler(new STFViewHandlerImpl());
//Register the new lifecycle with the factory with a unique
//name "STFLifecycle"
factory.addLifecycle("STFLifecycle", stfLifecycleImpl);
lifecycleId 硬编码为 STFLifecycle 。实际上不是这样。当您回过头分析 清单 9时就会清楚。 FacesServlet 从在 web.xml 文件中声明的上下文参数中得到名为 javax.faces.lifecycle.LIFECYCLE_ID 的 lifecycle ID,如下所示:<param-name>javax.faces.lifecycle.LIFECYCLE_ID</param-name>
<param-value>STFLifecycle</param-value>
</context-param>
<listener-class>foo.bar.stf.application.STFContextListener
</listener-class>
</listener>
|
|
|
|
|
|
|
|
|
一个简单的jQuery插件ajaxfileupload实现ajax上传文件例子
页面代码:
<script type="text/javascript">
function ajaxFileUpload(){
$.ajaxFileUpload({
url:'update.do?method=uploader',//需要链接到服务器地址
secureuri:false,
fileElementId:'houseMaps',//文件选择框的id属性
dataType: 'xml', //服务器返回的格式,可以是json
success: function (data, status)
{
$('#result').html('添加成功');
},
error: function (data, status, e)
{
$('#result').html('添加失败');
}
});
}
</script>
public ActionForward uploader(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response) {
UpFormForm upFormForm = (UpFormForm) form;
FormFile ff = upFormForm.getHouseMaps();
try {
InputStream is = ff.getInputStream();
File file = new File("D:/" + ff.getFileName()); // 指定文件存储的路径和文件名
OutputStream os = new FileOutputStream(file);
byte[] b = new byte[1024];
int len = 0;
while ((len = is.read(b)) != -1) {
os.write(b, 0, len);
}
os.close();
is.close();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}